








-
进程间通信,其实是通过内核的数据结构完成的,主要用于在一台linux上两个进程之间的通信。但是,一旦超出一台机器的范畴,我们就需要一种跨进程的通信机制。
-
一台机器将自己想要表达的内容,按照某种约定好的格式发送出去,当另一条机器收到这些信息后,也能够按照约定好的格式解析出来,从而准确、可靠的获得发送方想要表达的内容。这种约定好的格式就是网络协议。
准备一个场景
如下场景:Linux 服务器 A 和 Linux 服务器 B 处于不同的网段,通过中间的 Linux 服务器作为路由器进行转发。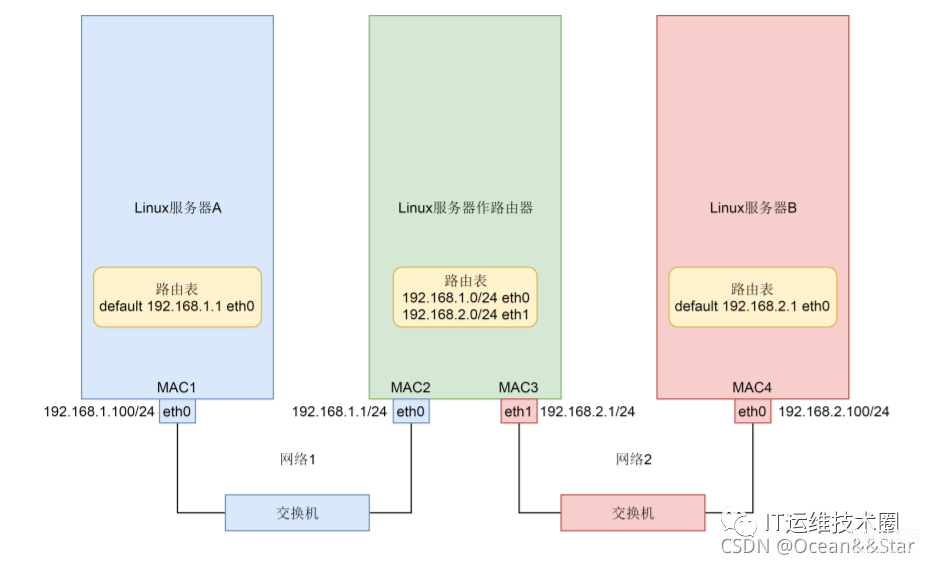
说起网络协议,我们必须要先了解一下两中网络协议模型,一种是OSI的标准七层模式,一种是业界标准的TCP/IP模型。它们之间的对应关系如下图:
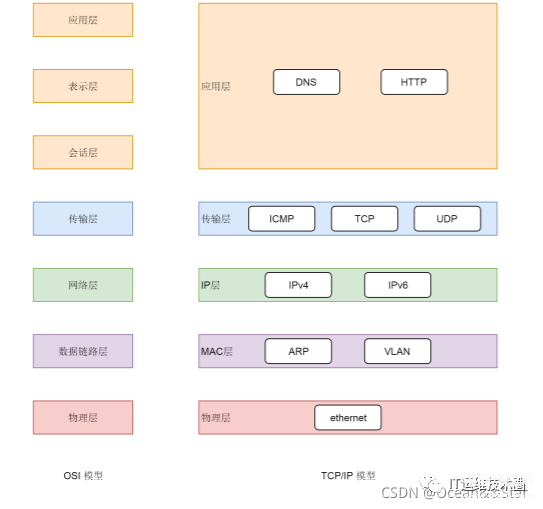
为什么网络要分层呢?
-
因为网络环境过于复杂,不是一个能够集中控制的体系。
-
全球数以亿计的服务器和设备各有各的体系,但是都可以通过同一套网络协议栈通过切分成多个层次和组织,来满足不同服务器和设备的通信需求。
我们这里简单介绍一下网络协议的几个层次。
(1)我们先从第三层,网络层开始。
-
网络层也叫做IP层,里面由IP地址
-
连接到网络上的每一个设备都至少有一个IP地址,用于定位这个设备。IP地主之类似互联网上的邮寄地址,具有全局定位功能
-
比如说如果要访问美国的一个地址,可以从身边的网络出发,通过不断的打听道路,经过多个网络,最终到达目的地址,和快递员送包裹的过程差不多。打听道路的协议也在第三次,成为路由协议(routing protocol),将网络包从一个网络转发到另一个网络的设备叫做路由器。
-
总的来说,第三层干的事情,就是网络包从一个起使的IP地址,沿着路由协议指出来道路,经过多个网络,通过多次路由器转发,到达目的IP地址
(2)从第三层往下看,可以看到数据链路层
-
数据链路层可以叫做二层或者MAC层
-
所谓MAC,就是每个网卡都有一个唯一的硬件地址(不绝对唯一,相对大概率唯一即可,类比UUID)。这虽然也是一个地址,但是这个地址是没有全局地位功能的
-
就像给你送外卖的小哥,不可能根据手机尾号找到你家,但是手机尾号有本地定位功能的,只不过这个定位主要靠“吼”。外卖小哥到了你的楼层就开始大喊:“尾号 xxxx 的,你外卖到了!”
-
MAC地址的定位功能局限在一个网络里面,也就是同一个网络号下的IP地址之间,可以通过MAC进行定位和通信。从IP地址获取MAC地址要通过ARP协议,是通过在本地发送广播包,也就是“吼”,获得MAC地址
-
由于同一个网络内的机器数量有限,通过MAC地址的好处就是简单。匹配上MAC地址就接收,匹配不上就i不接收,没有什么所谓路由协议这样复杂的协议。当然坏处就是,MAC地址的作用范围不能出本地网络,所以一旦跨网络通信,虽然IP地址保存不变,但是MAC地址每经过一个路由器就要变一次。
-
我们看前面的图。服务器 A 发送网络包给服务器 B,原 IP 地址始终是 192.168.1.100,目标 IP 地址始终是 192.168.2.100,但是在网络 1 里面,原 MAC 地址是 MAC1,目标 MAC 地址是路由器的 MAC2,路由器转发之后,原 MAC 地址是路由器的 MAC3,目标 MAC 地址是 MAC4。
-
所以第二层干的事情,就是网络包在本地网络中的服务器之间定位和通信的机制
(3)从第二层往下看就是第一层,物理层,这一层就是物理设备。比如网线
(4)从第三层往上看,就是传输层,这里面由两个著名的协议TCP和UDP。
-
在IP层的代码逻辑中,仅仅负责数据从一个IP地址发送到另一个IP地址,丢包、乱序、重传、拥塞,这些IP层都不管。处理这些问题的代码逻辑写在了传输层的TCP协议里面
-
TCP是可靠传输协议:因为第一层到第三层都是不可靠的,网络包说丢就丢,是TCP这一层通过各种编号、重传等机制,让本来不可靠的网络对于更上层来讲,变得”看起来“可靠
(5)从第四层传输层再往上,就要区分网络包是发给哪个应用。在传输层TCP和UDP协议里面,都有端口的概念,不同的应用监听不同的端口。
应用层和内核互通的机制,就是通过socket系统调用。那socket属于那一层呢?其实它哪一层都不属于,它属于操作系统的概念,而非网络协议分层的概念。只不过操作系统选择对于网络协议的实现模式是,二到四层的处理代码在内核里面,七层的处理代码让应用自己去做,两者需要跨内核态和用户态通信,就需要一个系统调用完成这个衔接,这就是socket
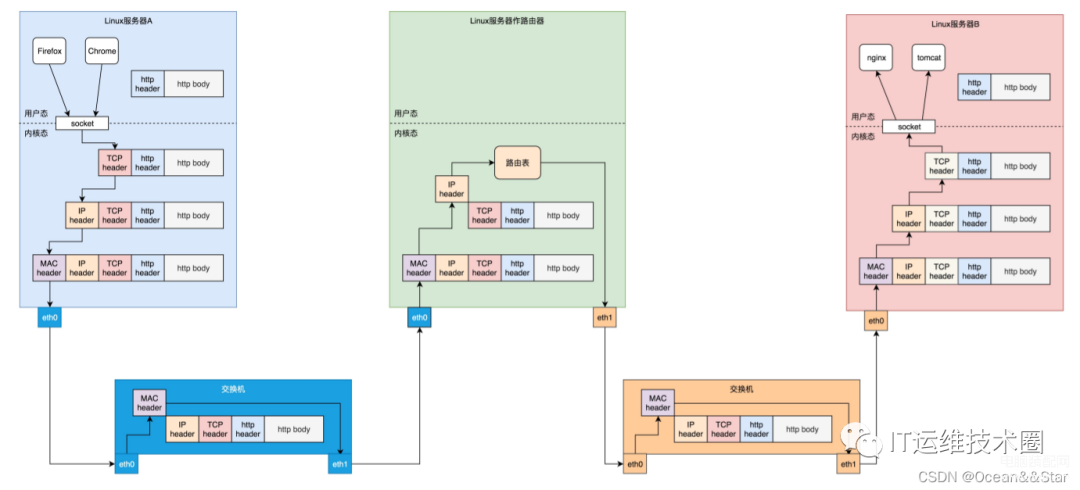
网络分完层之后,对于数据包的发送,就是层层封装的过程。
如下图:
-
在linux服务器B上部署的服务端nginx和tomcat,都是通过socket监听80和8080端口。这个时候,内核的数据结构就知道了。如果遇到发送到这两个端口的,就发送给这两个进程
-
在 Linux 服务器 A 上的客户端,打开一个 Firefox 连接 Ngnix。也是通过 Socket,客户端会被分配一个随机端口 12345。同理,打开一个 Chrome 连接 Tomcat,同样通过 Socket 分配随机端口 12346。
-
在客户端浏览器,我们将请求封装为HTTP协议,通过socket发送到内核。内核的网络协议栈里面,在TCP层创建用于维护连接、序列号、重传、拥塞控制的数据结构,将HTTP包加上TCP层,发送给IP层,IP层加上IP头,发送给MAC层,MAC层加上MAC头,从硬件网卡发出去
-
网络包会先到达网络1的交换机。我们常称交换机为二层设备,这是因为,交换机只会处理到第二层,然后它会将网络包的MAC头拿下来,发现目标MAC是在自己右边的网口,于是就从这个网口发出去
-
网络包会到达中间的linux路由器,它左边的网卡会收到网络包,发现MAC地址匹配,就交给IP层,在IP层根据IP头的信息,在路由表中查找下一跳在哪里,应该从哪个网口发出去。在这里,最终会从右边的网口发出去。我们常把路由器称为三层设备,因为它只会处理第三层
-
从路由器右边的网口发出去的包会到网络2的交换机,还是会经历一次二层的处理,转发到交换机右边的网口
-
最终网络包会被转到linux服务器B,它发现MAC地址匹配,就将MAC头取下来,交给上一层。IP层发现IP地址匹配,将IP头取下来,交给上一层。TCP层会根据TCP头中的序列号等信息,发现它是一个正确的网络包,就会将网络包缓存起来,等待应用层的读取。
-
应用层通过socket监听某个端口,因而读取的时候,内核会根据TCP头中的端口号,将网络包发给相应的应用
-
HTTP 层的头和正文,是应用层来解析的。通过解析,应用层知道了客户端的请求,例如购买一个商品,还是请求一个网页。当应用层处理完 HTTP 的请求,会将结果仍然封装为 HTTP 的网络包,通过 Socket 接口,发送给内核。
-
内核会经过层层封装,从物理网口发送出去,经过网络 2 的交换机,Linux 路由器到达网络 1,经过网络 1 的交换机,到达 Linux 服务器 A。在 Linux 服务器 A 上,经过层层解封装,通过 socket 接口,根据客户端的随机端口号,发送给客户端的应用程序,浏览器。于是浏览器就能够显示出一个绚丽多彩的页面了。
socket接口大多数情况下操作的是传输层,更底层的协议不用它来操心,这就是分层的好处。
在传输层有两个主流的协议TCP和UDP,所以我们的socket程序设计也是主要操作这两个协议。这两个协议的区别是什么呢?通常的答案是下面这样的
-
TCP是面向连接的,UDP是无连接的
-
TCP提供可靠交付,无差错、不丢失、不重复,并且按序到达;UDP不提供可靠交付,不保证不丢失,不保证按顺序到达
-
TCP是面向字节流的,发送时发的是一个流,没头没尾;UDP是面向数据报的,一个一个的发送
-
TCP可以提供流量控制和拥塞控制,即防止对端被压垮,也防止网络被压垮
这些答案没有问题,但是没有到达本质,也经常会让人产生错觉。比如,下面这些问题:
-
所谓的连接,容易让人误以为,使用 TCP 会使得两端之间的通路和使用 UDP 不一样,那我们会在沿途建立一条线表示这个连接吗?
-
我从中国访问美国网站,中间这么多环节,我怎么保证连接不断呢?
-
中间有个网络管理员拔了一根网线不就断了吗?我不能控制它,它也不会通知我,我一个个人电脑怎么能够保持连接呢?
-
还让我做流量控制和拥塞控制,我既管不了中间的链路,也管不了对端的服务器呀,我怎么能够做到?
-
按照网络分层,TCP 和 UDP 都是基于 IP 协议的,IP 都不能保证可靠,说丢就丢,TCP 怎么能够保证呢?
-
IP 层都是一个包一个包的发送,TCP 怎么就变成流了?
从本质上连接,所谓的建立连接,其实是为了在客户端和服务端维护连接,而建立一定的数据结构来维护双方交互的状态,并用这些的数据结构来保证面向连接的特性。TCP无法左右中间的任何通路,也没有什么虚拟的连接,中间的通路根本意识不到两端使用了TCP还是UDP。
所谓的连接,就是两端数据结构状态的协同,两边的状态能够对得上。符号TCP协议的规则,就认为连接存在;两面状态对不上,连接就算断了
流量控制和拥塞控制其实就是根据收到的对端的网络包,调整两端数据结构的状态。TCP协议的设计理论上认为,这样调整了数据结构的状态,就能进行流量控制和拥塞控制了,其实在通道上是不是真的做到了,谁也管不着。
所谓的“可靠”,就是两端的数据结构做的事情。不丢失其实是数据结构在“点名”,顺序到达其实是数据结构在“排序”,面向数据流其实是数据结构将零散的包,按照顺序捏成一个流发给应用层。总而言之,“连接”两个字让人误以为功夫在通路,其实功夫在两端。
当然,无论是用 socket 操作 TCP,还是 UDP,我们首先都要调用 socket 函数。
int socket(int domain, int type, int protocol);
socket函数用于创建一个socket的文件描述符,唯一标识一个socket。我们把它叫做文件描述符,因为在内核中,我们会创建类似文件系统的数据结构,并且后继的操作都有用到它。
socket 函数有三个参数。
-
domain:表示使用什么 IP 层协议。AF_INET 表示 IPv4,AF_INET6 表示 IPv6。
-
type:表示 socket 类型。SOCK_STREAM,顾名思义就是 TCP 面向流的,SOCK_DGRAM 就是 UDP 面向数据报的,SOCK_RAW 可以直接操作 IP 层,或者非 TCP 和 UDP 的协议。例如 ICMP。
-
protocol 表示的协议,包括 IPPROTO_TCP、IPPTOTO_UDP。
通信结束后,我们还要像关闭文件一样,关闭 socket。
针对TCP应该如何编程
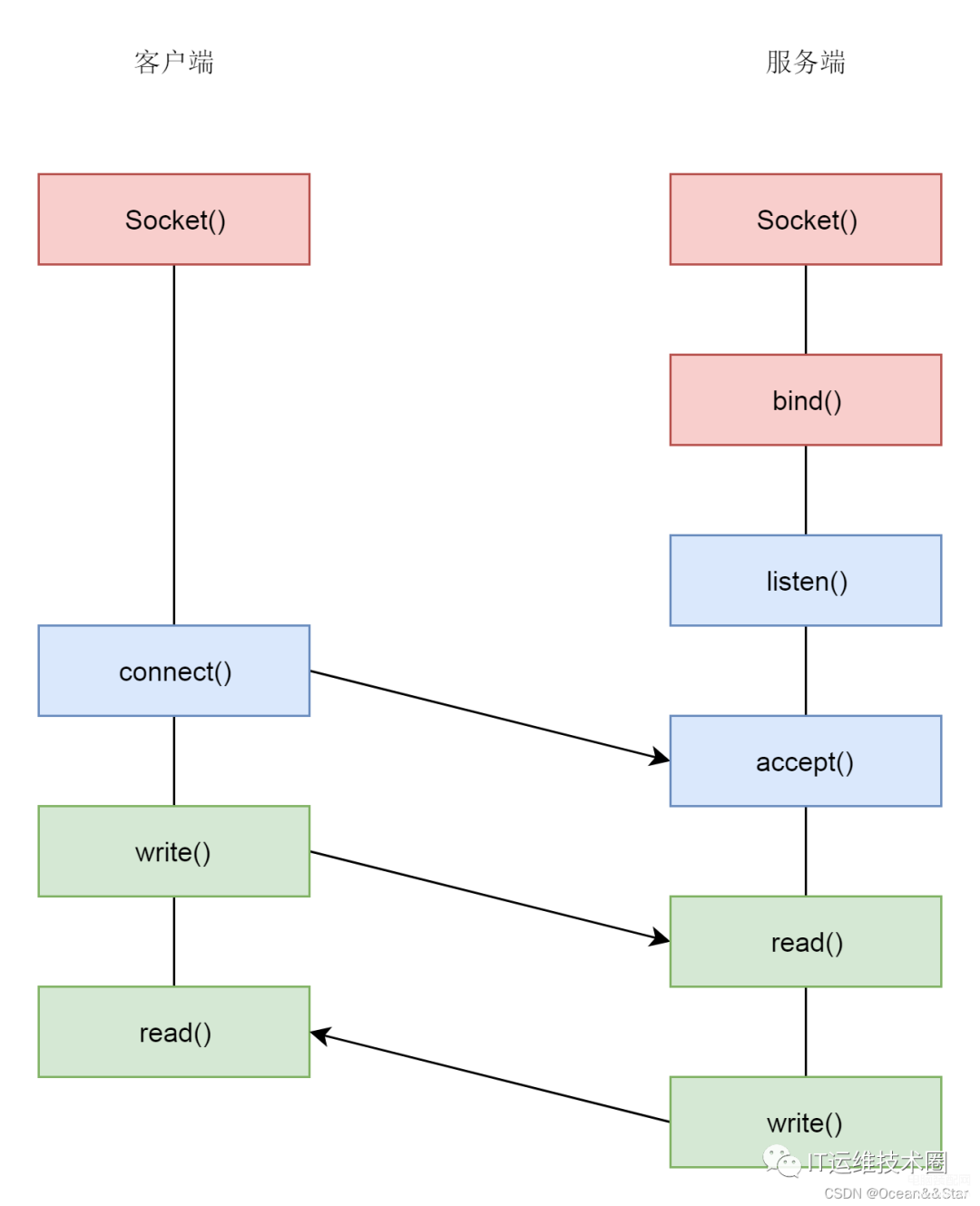 TCP服务端要先监听一个端口,一般是调用bind函数,给这个socket赋予一个端口和IP地址:
TCP服务端要先监听一个端口,一般是调用bind函数,给这个socket赋予一个端口和IP地址:
int bind(int sockfd, const struct sockaddr *addr,socklen_t addrlen); struct sockaddr_in { __kernel_sa_family_t sin_family; __be16 sin_port; struct in_addr sin_addr; unsigned char __pad[__SOCK_SIZE__ - sizeof(short int) - sizeof(unsigned short int) - sizeof(struct in_addr)];}; struct in_addr { __be32 s_addr;};
其中,sockfd 是上面我们创建的 socket 文件描述符。在 sockaddr_in 结构中,sin_family 设置为 AF_INET,表示 IPv4;sin_port 是端口号;sin_addr 是 IP 地址。
服务端所在的服务器可能有多个网卡、多个地址,可以选择监听在一个地址,也可以监听0.0.0.0表示所有的地址都监听。服务端一般要监听在一个众所周知的端口上。
客户端要访问服务端,就一定要事先直到服务端的端口。当然,只有客户端主动去连接别人,别人不会主动连接客户端,没有人关心客户端监听到了哪里,所以客户端不需要bind。
上面代码中的数据结构,里面的变量名称都有“be”两个字母,代表的意思是“big-endian”。如果在网络上传输超过 1 Byte 的类型,就要区分大端(Big Endian)和小端(Little Endian)。
假设,我们要在 32 位 4 Bytes 的一个空间存放整数 1,很显然只要 1 Byte 放 1,其他 3 Bytes 放 0 就可以了。那问题是,最后一个 Byte 放 1 呢,还是第一个 Byte 放 1 呢?或者说,1 作为最低位,应该放在 32 位的最后一个位置呢,还是放在第一个位置呢?
最低位放在最后一个位置,我们叫作小端,最低位放在第一个位置,叫作大端。TCP/IP栈是按照大端来设计的,而x86基本是小端设计,因而发出去时需要做一个转换。
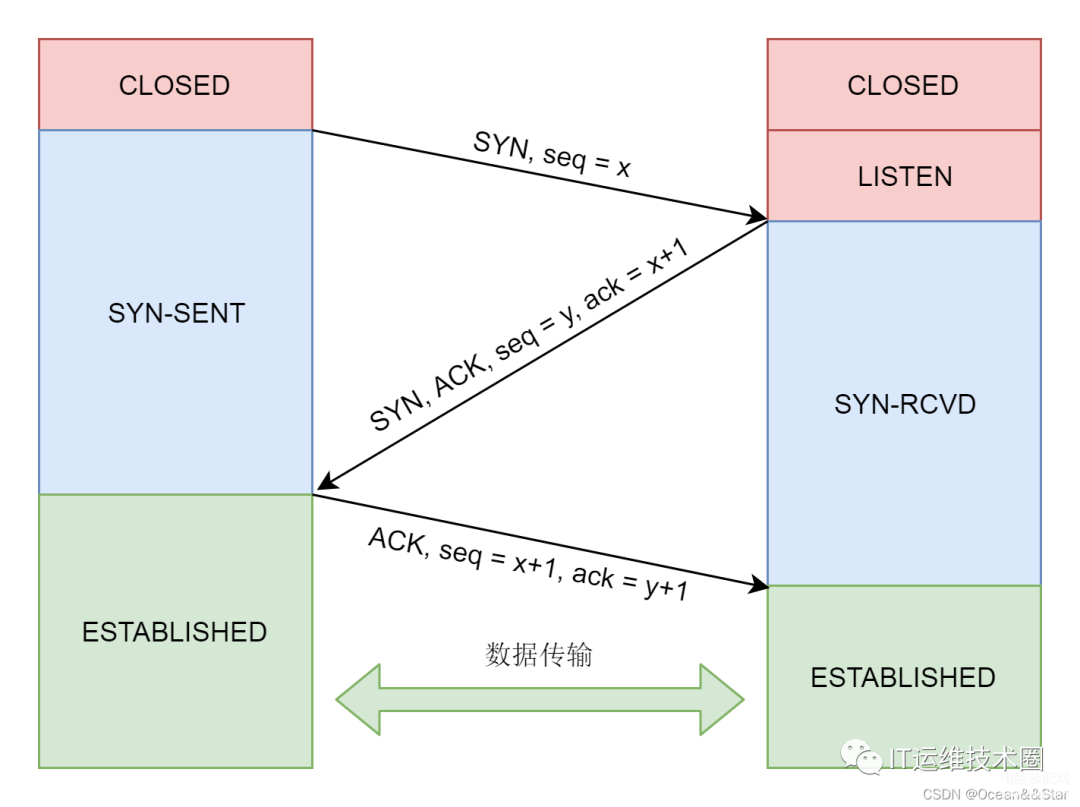
接下来,就要建立TCP的连接了,也就是著名的三次握手,其实就是将客户端和服务端的状态通过三次网络交互,达到初始状态是协同的状态。
 接下来,服务端要调用 listen 进入 LISTEN 状态,等待客户端进行连接。
接下来,服务端要调用 listen 进入 LISTEN 状态,等待客户端进行连接。
int listen(int sockfd, int backlog);
连接的建立过程,也就是三次握手,是TCP层的动作,是在内核完成的,应用层不需要参与。
接着,服务端只需要调用accept,等待内核完成了至少一个连接的建立,才返回。如果没有一个连接完成了三次握手,accept就一直等待;如果有多个客户端发起连接,并且在内核里面完成了多个三次握手,建立了多个连接,这些连接会被放在一个队列里面。accept会从队列中取出一个来进行处理。如果想要进一步处理其他连接,需要调用多次accept,所以accept往往在一个循环里
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
接下来,客户端可以通过 connect 函数发起连接。
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
我们先在参数中指明要连接的IP地址和端口号,然后发起三次握手。内核会给客户端分配一个临时的端口。一旦握手成功,服务端的accept会返回另一个socket。
这里需要注意的是,监听的socket和真正用来传输数据的socket,是两个socket,一个叫做监听socket,一个叫做已连接socket。成功连接建立之后,双方开始通过read和write函数来读写数据,就像完一个文件流里面写东西一样。
针对UDP应该如何编程
接下来我们来看,针对 UDP 应该如何编程。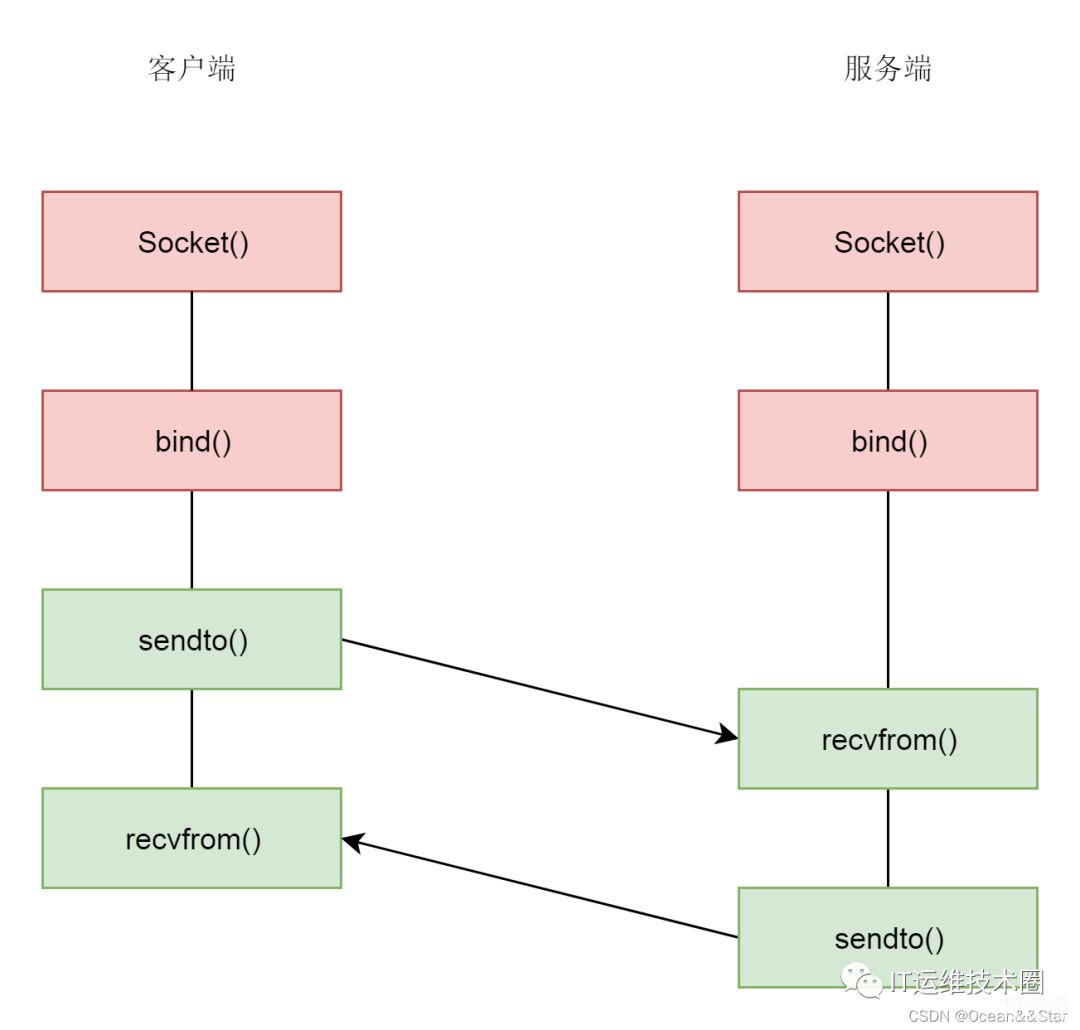 UDP是没有连接的,所以不需要三次握手,也就不需要调用listen和connect,但是UDP的交互仍然需要IP地址和端口号,因而也需要bind。
UDP是没有连接的,所以不需要三次握手,也就不需要调用listen和connect,但是UDP的交互仍然需要IP地址和端口号,因而也需要bind。
对于UDP来讲,没有所谓的连接维护,也没有所谓的连接的发起方和接收方,甚至都不存在客户端和服务端的概念。大家都是客户端,也同时是服务端。只要有一个socket,多台机器就可以任意通信,不存在哪两台机器是属于一个连接的概念。因此,每一个UDP的socket都需要bind,。每次通信时,调用 sendto 和 recvfrom,都要传入 IP 地址和端口
源链接:
https://blog.csdn.net/zhizhengguan/article/details/121640391
作者:网络
编辑:IT运维技术圈
波哥
IT行业近二十年的IT老炮。常年潜伏于国企、各一二线大厂中。硬件集成入行,直至虚拟技术、容器化。岗位历经系统集成、DBA、全栈开发、sre、项目经理、产品经理、部门总监。
主要作品:
IT类资源汇聚门户:https://www.98dev.com
各大短视频平台:98dev
各大主要技术论坛博客:IT运维技术圈
长视频教学作品:《波哥讲网络》《波哥讲git》《波哥讲gitlab》
小程序:IT面试精选
构建技术社区:+V itboge1521 入学习交流群